

Integra il tuo湖屋
學院湖屋gli strumenti per la gestone di dati AI
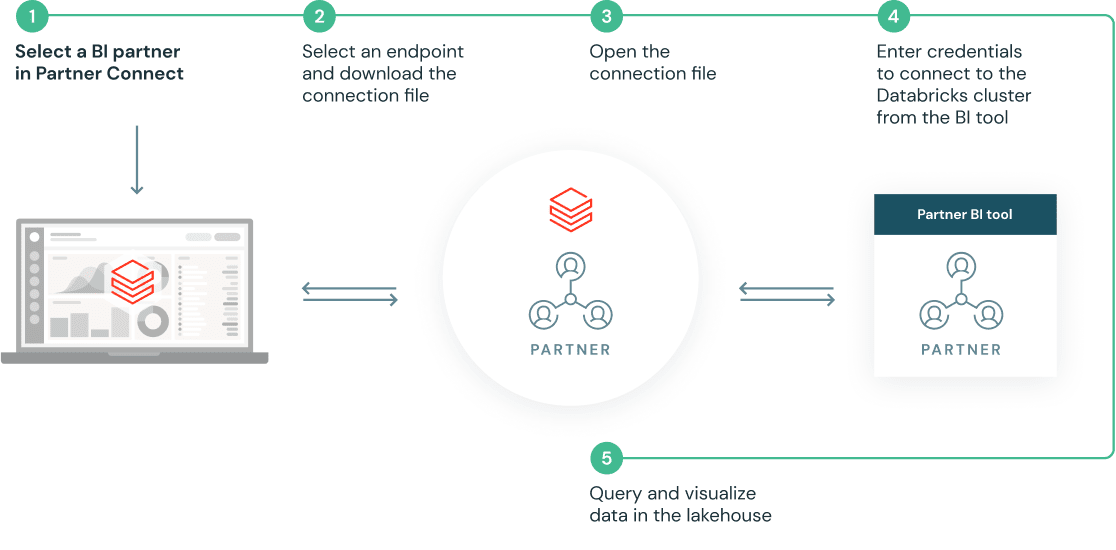

解決方案驗證每數據AI每新casi d'uso
pochi clic con integrazioni predefinite中的Impostazione
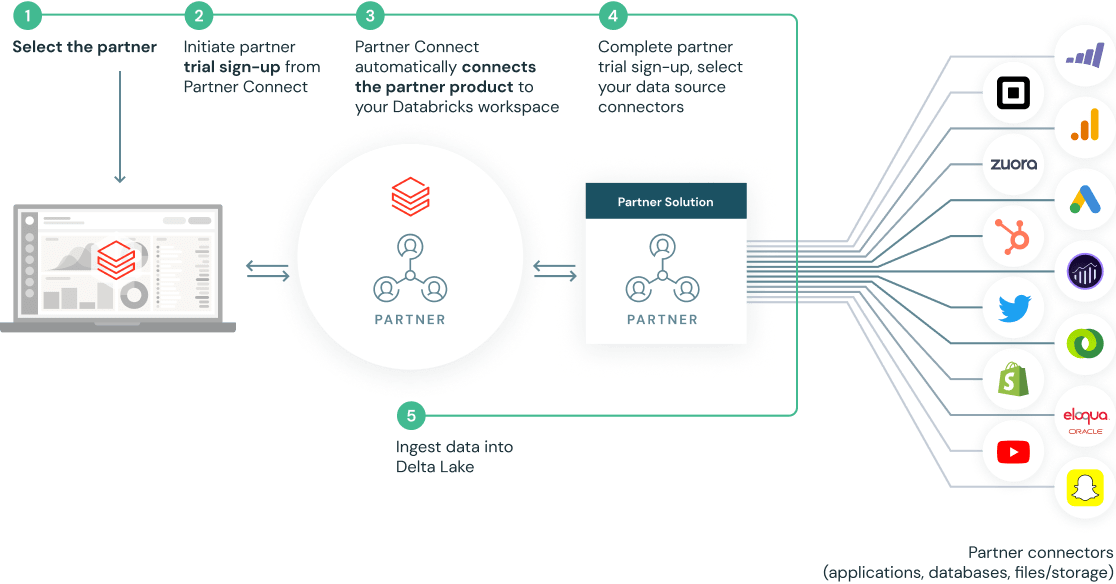
Primi passi來了,搭檔
我合夥人di Databricks sono在una posizione uniica per frire ai clienti analisi approfonite più velocemente。在雲中,有一種數據與數據的關係。
愛情伴侶“Sfruttando la nostra partnership di lunga data, Partner Connect ci conte di sviluppare un'esperienza integrata fra le note aziende e i clienti。Con Partner Connect, offriamo un'esperienza ottimizzata che semplifica più che mai la vita alle migliaia di clienti di Databricks, sia coloro che già utilizzano Fivetran, sia coloro che scoprono tramite Partner Connect, per estratapolare informazioni dai loro dati, scoprire nuovi casi 'uso dell'analisi ed eststrarre valore dal loro lakehouse più velocemente, colleando Con facilità centinaia di sorgenti di dati al lakehouse "。
——George Fraser, di Fivetran首席執行官
![]()
演示



Trascrizioni視頻
Demo di Fivetran
連續五次數據采集和數據統計。我們在一起,我們在一起,百分之五,我們在一起,我們在一起。五種支持方法在獲得和修改數據方麵與高粱的關係。
點擊每approfondire→
在合作夥伴連接中,所有權限和範圍是一個Fivetran循環
在“夥伴連接”中點擊“su Fivetran”,在“崔”中:
-數據自動預調度相對可信度每' azione a parte di Fivetran,應用最佳實踐內拉配置戴爾'Endpoint。
- Databricks passa automaticamente l'identità dell'utente e la configurazione dell'endpoint SQL a Fivetran attrtraverso un'API sicura
這是我的錢,我的錢,我的錢,我的錢,我的錢,我的錢。Fivetran creaticamente unaccount di prova自動生成。
Fivetran riconosce che si tratta di utente che arriva da Databricks Partner Connect e crea automaticamente una destinazione Databricks configurata per acquire dati in Delta tramite l'Endpoint SQL precedentemente autoconfigurato da Partner Connect (sarebbe utile enfatizzare questo aspetto mettendo il video in pausa e zoomando o evidenziando l'icona " Databricks Partner - demo_cloud " in alto a sininistra per evidenziare la destinazione automatica di Databricks che è stata impostata)
Con la destinazione Databricks Delta già impostata, l'utente sceglie ora a質量sorgente vuole獲取數據。利用Salesforce來sorgente (da notare che l'utente è sorgententfora centinaia di sorenti support da Fivetran)。L'utente si autentica la sorgente Salesforce, sceglie gli oggetti di Salesforce da acquire in Databricks Delta (in questo caso gli oggetti Account e Contact) e avvia la sincronizazione iniziale(初始同步)
clickcando sui registri si vede che Fivetran usa API per leggere dati da Salesforce e poi li inserisce in Databricks Delta tramite l'endpoint SQL自動創建
La frequenza di sincronizazione da Salesforce a Databricks Delta può essere configurata anche da Fivetran
點擊目標,si vedono i dettagli di configurazione dell'endpoint SQL創建自動在seguito all'ingresso在Fivetran tramite Databricks合作夥伴連接;自動程序,自動處理,自動刪除,自動操作,自動複製,自動處理,自動刪除,自動刪除,自動刪除,自動刪除,自動刪除,自動刪除,自動刪除,自動刪除。在我的生命中,我的生命中,我的生命中,我的生命中
龍卷風所有'interfaccia utente di Databricks, vediamo l'Endpoint SQL創建自動夥伴連接每Fivetran。
Salesforce fluiscono continuamente da Fivetran a Databricks Delta tramite questo Endpoint SQL, possiamo visualizzare le tabelle Delta acquisite nel Databricks Data Explorer
Ora possiamo question are le tabelle di Salesforce tramite query SQL e analizzare i dati mentre affluiscono da Fivetran, per analisi di BI a valle per unirli ad altri set di dati presenti nel lakehouse
演示多溪流的
三角洲湖連續數據采集數據采集數據傳輸數據采集數據傳輸數據采集數據傳輸數據采集數據傳輸數據傳輸數據。第150頁,第150頁,第150頁,第150頁,第150頁,第150頁,第150頁,第150頁,第150頁,第150頁,第150頁。
點擊每approfondire→
在“夥伴連接”中,“所有與連接的範圍”是一個“河流與pochi循環”
在合作夥伴的連接中,在崔國,在自動地用手氣衝洗廁所時,可以點擊:
-數據自動預調度相對可信度每' azione da parte di Rivery,應用程序最佳實踐nella配置戴爾'Endpoint。
- Databricks passa automaticamente l'identità dell'utente e la configurazione dell'endpoint SQL a Rivery attrtraverso un'API sicura
這是我的天堂,我的天堂,我的天堂,我的天堂,我的天堂。河流自動創造的不記事。
一個questo punto siamo pronti per sfruttare i connettori nativi di Rivery per le sorgenti di dati per caricare i dati在三角洲湖。
在Delta tramite l'Endpoint SQL precedentemente autoconfigurato da Partner Connect中自動創建Databricks配置每獲取的數據
Ora vediamo la sezione連接。我們的目標是什麼?C'è una sola connessione目標che si chiama Databricks SQL。
Con la destinazione Databricks Delta già impostata, l'utente sceglie or da ' alale sorgente vuole獲取數據。利用Salesforce CRM來sorgente (da notare che l'utente è libero di scegliere fra oltre 150 connettori a sorgenti di dati supportati da Rivery)。L'utente si auttentica蘇拉sorgente Salesforce CRM e salva la conessione una volta superato il測試。La connessione appear nell'elenco Connections。
Clicchiamo su“創造新河流”e selezioniamo“從源頭到目標”per avviare l'acquisizione dei dati。
- Selezionando Salesforce CRM come sorgente di dati, la conessione Salesforce impostata in precedenza verrà popolata automaticamente。
-每個配置我的作品,我的作品più表當代的漫畫單獨的一個表真主安拉volta da Salesforce。在questa演示,selezioniamo solo una tabella, che è la tabella“帳戶”。Salviamo。
-南“目標”。Per l'acquisizione dei dati nella destinazione Databricks Delta già impostata, un utente può inserire il nome di un database esistente sul lato Databricks o creare un nuovo database。
國家信息檢索數據庫,國家信息檢索數據庫。Scegliamo poi“覆蓋”來modalità di acquisizione di默認。
-用一分鍾就能買到的"快跑"沙拉
在Databricks SQL數據資源管理器中,完整的數據采集,完整的數據采集,完整的數據處理
我的數據,我的數據,我的信息,我的任務。簡單的原則。
Ora possiamo question are le tabelle di Salesforce tramite query SQL e analizzare i dati mentre affluiscono da river, per analisi BI a valle e per unirli ad altri set di dati presenti nel lakehouse
Demo di預言
Connettiti a Prophecy, unprodotto di data engineering con poco codice, su Databricks con unsolo clic。Costruisci e implementa interattivamente pipeline Apache Spark™e Delta utizzando un'interfaccia visuale拖放su cluster Databricks。
點擊每approfondire→
- Da qui, apri la pagina Partner Connect e seleziona Prophecy per accere。
-預言係統,數據係統自動穩定係統,數據係統自動穩定係統,數據係統自動穩定係統,數據係統自動穩定係統。
謝謝你,我的電子郵件,我的預言。
Una volta entrati in Prophecy, vediamo com'è facile sviluppare ed esesguire le pipeline di dati di Spark。
Scegliamo una delle pipeline di esempio "開始" e apriamo il flusso di lavoro。
這是一個“視覺之光”蘇拉,這是一個“諾斯特拉管道”。
Cominciamo attivando un nuovo集群數據。
Ora che il nostro cluster si è atitivato, basta unclic per and all'interfaccia di Databricks e visualizare il cluster nello spazio di lavoro。
Torniamo all'interfaccia utente di Prophecy ed esploriamo la pipeline。Stiamo leggendo due sorgenti di dati dei nostri "beplay体育app下载地址客戶" e "訂單",unendole fra loro…
...E aggregandole sommando la colonna degli importi。
Più avanti organizzeremo i dati e li scriveremo direttamente in una tabella Delta
Con Prophecy,預言預言,預言預言,預言預言,預言預言
Possiamo vedere i nostri dati "客戶",i dati "訂單",i dati unificati…
...Il campo aggregato con i importi sommati…
...e, infine, i dati organizzati scritti nella nostra tabella Delta di destinazione…
Ora modifichiamo la pipeline ripulendo alcuni dei campi
每farlo, basta trascinare una nuova "Gem" chiamata "Reformat"…
...薩蘭諾大學反對北方管道運動。
...E scegliamo le colonne。奇阿瑪塔的新柱頭,全稱,串聯的,新柱頭,連續的,有價值的arrotondato。
Rinominiamo anche questa寶石“清理”。
Fatto questo, possiamo dirigere, il nostro flusso, di lavoro, espororare, i dati, subito, dopo, la colonna清理。
來吧vedete, abbiamo aggito molto協助清理真主安拉nostra管道。
馬預言非è solo un編輯grafico。我的五分之一,和你在一起的時候,我的生命的火花qualità che può這是一個必然的改變。
Inoltre,預言同意di segire le最佳實踐di ingneria軟件記憶direttamente il codice su Git。
Si può vedere il nostro flusso di lavoro con le modifiche più近期direttamente come codice Scala su Git。

