
本文解釋如何在Delta Lake中觸發分區修剪合並成(AWS|Azure|GCP)的查詢。
分區修剪是一種優化技術,用於限製查詢檢查的分區數量。
討論
合並成與Delta表一起使用時,是一個開銷很大的操作。如果不對底層數據進行分區並適當地使用它,查詢性能可能會受到嚴重影響。
主要的經驗是:如果您知道哪個分區a合並成查詢需要檢查,您應該在查詢中指定它們,以便執行分區修剪。
演示:沒有分區修剪
這裏有一個表現不佳的例子合並成沒有分區修剪的查詢。
首先創建下麵的Delta表,稱為delta_merge_into:
%scala val df = spark.range(30000000) .withColumn("par", ($"id" % 1000).cast(IntegerType)) .withColumn("ts", current_timestamp()) .write .format("delta") .mode("overwrite") .partitionBy("par") .saveAsTable("delta_merge_into")
然後將一個DataFrame合並到Delta表中,以創建一個名為更新:
%scala val updatesTableName = "update" val targetTableName = "delta_merge_into" val updates = spark.range(100)。withColumn("id", (rand() * 30000000 * 2).cast(IntegerType)) .withColumn("par", ($"id" % 2).cast(IntegerType)) .withColumn("ts", current_timestamp()) . dropduplasts ("id") updates.createOrReplaceTempView(updatesTableName)
的更新表有100行,三列,id,票麵價值,ts.的價值票麵價值總是1或0。
假設您運行以下簡單程序合並成查詢:
% scala火花。sql(s""" |MERGE INTO $targetTableName |USING $updatesTableName |ON $targetTableName。id = updatesTableName美元。id|WHEN MATCHED THEN | UPDATE SET $targetTableName.ts = $updatesTableName.ts |WHEN NOT MATCHED THEN | INSERT (id, par, ts) VALUES ($updatesTableName.id, $updatesTableName.par, $updatesTableName.ts) """.stripMargin)
查詢耗時13.16分鍾:
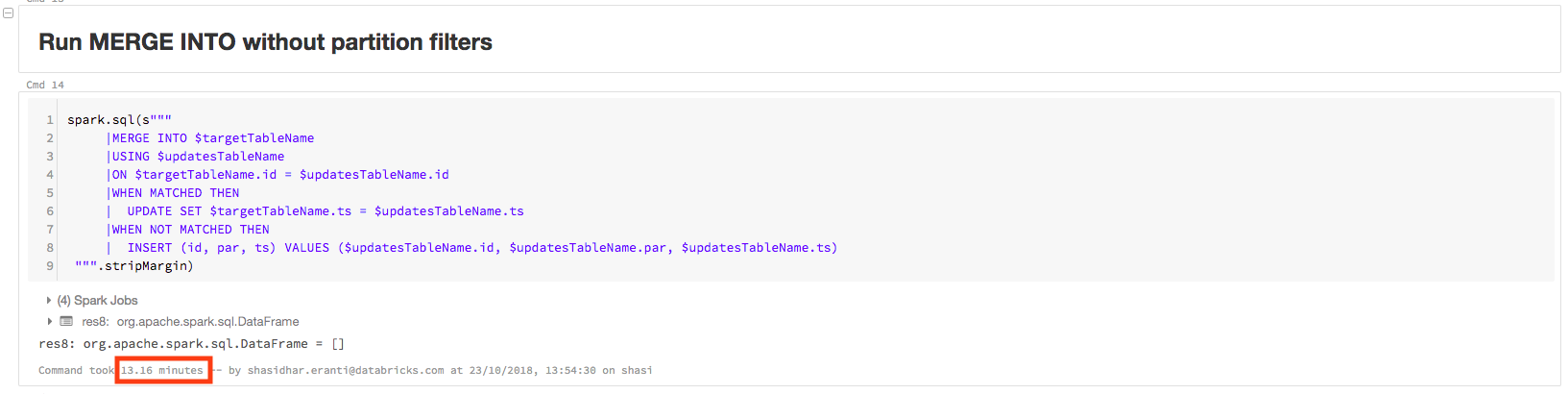
該查詢的物理計劃包含PartitionCount: 1000,如下圖所示。這意味著Apache Spark正在掃描所有1000個分區以執行查詢。這不是一個有效的查詢,因為更新數據的分區值隻有1而且0:
物理計劃= = = = * (5)HashAggregate(鍵=[],函數= [finalmerge_count(合並計算# 8452 l)計數(1)# 8448 l),輸出= [count # 8449 l]) + -交換SinglePartition + - * (4) HashAggregate(鍵=[],函數= [partial_count(1)計數# 8452 l),輸出= [count # 8452 l]) + - *(4)項目+ - *(4)過濾器(isnotnull (count # 8440 l) & & (count # 8440 l > 1)) + - * (4) HashAggregate(鍵= (_row_id_ # 8399 l),函數= [finalmerge_sum(合並和# 8454 l)和(cast(1 # 8434為bigint)) # 8439 l),output=[count#8440L]) +- *(3) HashAggregate(keys=[_row_id_#8399L], functions=[partial_sum(cast(one#8434 as bigint)) as sum#8454L], output=[_row_id_#8399L, sum#8454L]) +- *(3) Project [_row_id_#8399L, UDF(_file_name_#8404) as one#8434] +- *(3) BroadcastHashJoin [cast(id#7514 as bigint)], [id#8390L], Inner, BuildLeft, false:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)):+- *(2) HashAggregate(keys=[id#7514], functions=[], output=[id#7514]): +- Exchange hashpartitioning(id#7514, 200): +- *(1) HashAggregate(keys=[id#7514], functions=[], output=[id#7514]): +- *(1) Filter isnotnull(id#7514): +- *(1) Project [cast((rand(8188829649009385616) * 3.0E7) * 2.0) as int) as id#7514]:+- *(1) Range (0,100, step=1, partitions =36) +- *(3) Filter isnotnull(id#8390L) +- *(3) Project [id#8390L, _row_id_#8399L, input_file_name() AS _file_name_#8404] +- *(3) Project [id#8390L, addiically_increing_id () AS _row_id_#8399L] +- *(3) Project [id#8390L, par#8391, ts#8392] +- *(3) FileScan parquet [id#8390L, par# 8392,par#8391] Batched: true, DataFilters: [], Format: parquet, Location: TahoeBatchFileIndex[dbfs:/user/hive/warehouse/delta_merge_into], PartitionCount: 1000, PartitionFilters:[], PushedFilters: [], ReadSchema: struct
解決方案
重寫查詢以指定分區。
這合並成Query直接指定分區:
% scala火花。sql(s""" |MERGE INTO $targetTableName |USING $updatesTableName |ON $targetTableName。par IN(1,0)和$targetTableName。id = updatesTableName美元。id|WHEN MATCHED THEN | UPDATE SET $targetTableName.ts = $updatesTableName.ts |WHEN NOT MATCHED THEN | INSERT (id, par, ts) VALUES ($updatesTableName.id, $updatesTableName.par, $updatesTableName.ts) """.stripMargin)
現在,在同一個集群上完成查詢隻需要20.54秒:
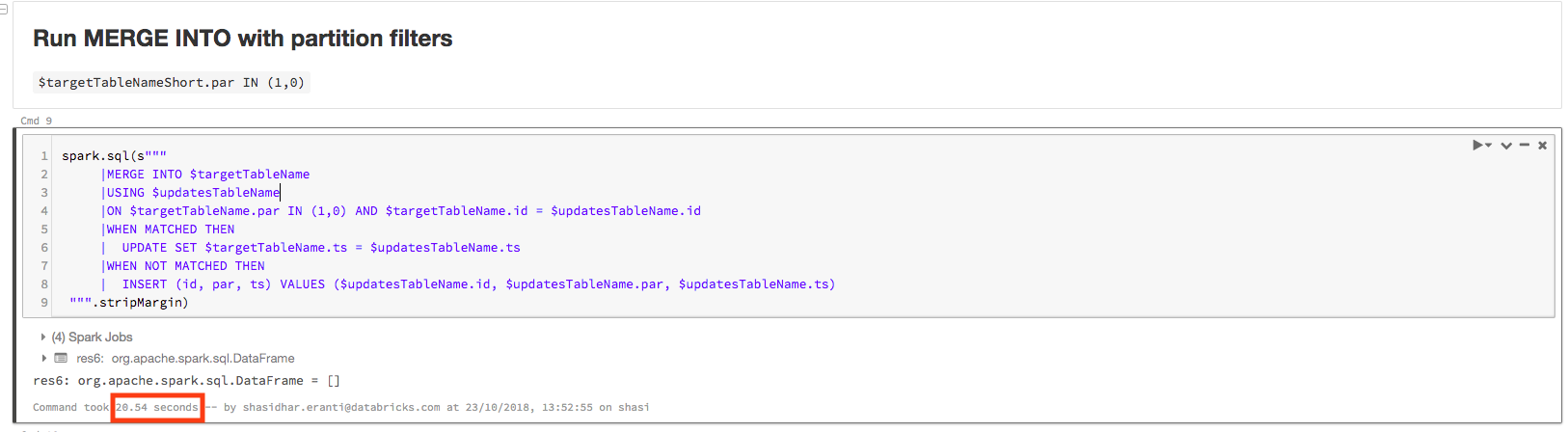
該查詢的物理計劃包含PartitionCount: 2,如下圖所示。隻要稍加改動,查詢速度就快了40多倍:
物理計劃= = = = * (5)HashAggregate(鍵=[],函數= [finalmerge_count(合並計算# 7892 l)計數(1)# 7888 l),輸出= [count # 7889 l]) + -交換SinglePartition + - * (4) HashAggregate(鍵=[],函數= [partial_count(1)計數# 7892 l),輸出= [count # 7892 l]) + - *(4)項目+ - *(4)過濾器(isnotnull (count # 7880 l) & & (count # 7880 l > 1)) + - * (4) HashAggregate(鍵= (_row_id_ # 7839 l),函數= [finalmerge_sum(合並和# 7894 l)和(cast(1 # 7874為bigint)) # 7879 l),output=[count#7880L]) +- *(3) HashAggregate(keys=[_row_id_#7839L], functions=[partial_sum(cast(one#7874 as bigint)) as sum#7894L], output=[_row_id_#7839L, sum#7894L]) +- *(3) Project [_row_id_#7839L, UDF(_file_name_#7844) as one#7874] +- *(3) BroadcastHashJoin [cast(id#7514 as bigint)], [id#7830L], Inner, BuildLeft, false:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)):+- *(2) HashAggregate(keys=[id#7514], functions=[], output=[id#7514]): +- Exchange hashpartitioning(id#7514, 200): +- *(1) HashAggregate(keys=[id#7514], functions=[], output=[id#7514]): +- *(1) Filter isnotnull(id#7514): +- *(1) Project [cast((rand(8188829649009385616) * 3.0E7) * 2.0) as int) as id#7514]:+- *(1) Range (0,100, step=1, partitions =36) +- *(3) Project [id#7830L, _row_id_#7839L, _file_name_#7844] +- *(3) Filter (par#7831 IN (1,0) && isnotnull(id#7830L,par#7831, _row_id_#7839L, input_file_name() AS _file_name_#7844] +- *(3) Project [id#7830L, par#7831, addiically_increing_id () AS _row_id_#7839L] +- *(3) Project [id#7830L, par#7831, ts#7832] +- *(3) FileScan parquet [id#7830L, par# 7830L, par# 7832,par#7831]批量:true, DataFilters: [], Format: parquet, Location:TahoeBatchFileIndex[dbfs:/user/hive/warehouse/delta_merge_into], PartitionCount: 2, PartitionFilters: [], PushedFilters: [], ReadSchema: struct