
本文描述如何訪問Azure磚與辛巴的JDBC驅動程序使用Azure廣告身份驗證。
這可能是有用的,如果你想使用一個Azure廣告用戶帳戶連接到Azure磚。
創建一個服務主體
創建一個服務主體在Azure廣告。服務主體獲得用戶的訪問令牌。
- 打開Azure門戶。
- 打開Azure活動目錄服務。
- 點擊應用程序注冊在左邊的菜單。
- 點擊新的注冊。
- 完整的表單並單擊注冊。
你的服務主體已經成功創建了。
配置服務主體的權限
- 打開創建的服務主體。
- 點擊API的權限在左邊的菜單。
- 點擊添加一個權限。
- 點擊Azure權利管理服務。
- 點擊委托權限。
- 選擇user_impersonation。
- 點擊添加權限。
- 的user_impersonation現在允許分配給你的服務主體。

更新服務主體清單
- 點擊清單在左邊的菜單。
- 尋找包含“allowPublicClient”財產。
- 將值設置為真正的。
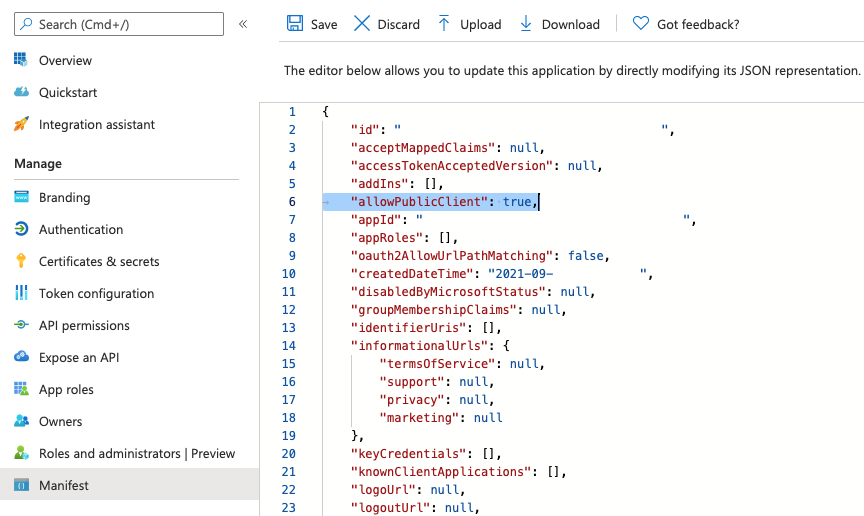
- 點擊保存。
下載和配置JDBC驅動程序
- 下載磚JDBC驅動程序。
- 配置JDBC驅動程序詳細的文檔。
獲得Azure廣告令牌
使用示例代碼獲取Azure廣告為用戶令牌。
替換的變量值,適合您的帳戶。
%從adal python導入AuthenticationContext authority_host_url = " https://login.microsoftonline.com/ " " # Azure磚azure_databricks_resource_id的應用程序ID = " 2 ff814a6 - 3304 - 4 - ab8 - 85 - cb - cd0e6f879c1d“#需要用戶輸入user_parameters ={“租戶”:“< tenantId >”,“client_id”:“< clientId >”,“用戶名”:“< user@domain.com >”,“密碼”:<密碼>}#配置AuthenticationContext #權威authority_url使用URL和承租者ID = authority_host_url + user_parameters(“承租人”)背景= AuthenticationContext (authority_url) # API調用來獲取令牌token_response =上下文。acquire_token_with_username_password (azure_databricks_resource_id user_parameters(“用戶”),user_parameters['密碼'],user_parameters [' client_id ']) access_token = token_response [' accessToken '] refresh_token = token_response (“refreshToken”)
通過Azure廣告令牌JDBC驅動程序
現在您已經用戶的Azure廣告令牌,你可以將它傳遞給JDBC驅動程序使用Auth_AccessToken在詳細的JDBC URL建築磚的連接URL驅動程序文檔。
這個示例代碼演示了如何通過Azure廣告令牌。
% #安裝python jaydebeapi pypi模塊(用於演示)導入jaydebeapi大熊貓作為pd導入導入操作係統os。環境(“路徑”)= " <路徑下載辛巴火花JDBC / ODBC驅動程序>“# JDBC連接字符串url = " JDBC:火花:/ /亞洲開發銀行- 111111111111 xxxxx.xx.azuredatabricks.net: 443 /違約;運輸方式= http; ssl = 1; httpPath = sql / protocolv1 / o / < workspaceId > / < clusterId >; AuthMech = 11; Auth_Flow = 0; Auth_AccessToken = {0} " .format (access_token)嚐試:康涅狄格州= jaydebeapi.connect (“com.simba.spark.jdbc。司機”,url)光標= conn.cursor() #執行SQL查詢SQL = " select * from <表>”cursor.execute (SQL)結果= cursor.fetchall () column_names = [x [0] x cursor.description) pdf = pd。DataFrame(結果、列= column_names)打印(pdf.head()) #取消以下兩行如果這段代碼運行在工作區中的磚連接IDE或筆記本。# df = spark.createDataFrame (pdf) # df.show()最後:如果光標不是沒有:cursor.close ()