問題
已創建VPC對等連接,並在對端網絡中配置了Amazon Redshift集群。當你嚐試訪問紅移集群時,你會得到以下錯誤:
錯誤信息:OperationalError: could not connect to server:連接超時
導致
以下情況會出現此問題:
- VPC對等配置錯誤。
- 由於安全組(SG)、網絡訪問控製列表(NACL)或其他路由問題,相應的端口在網絡組件級別被阻塞。
故障排除
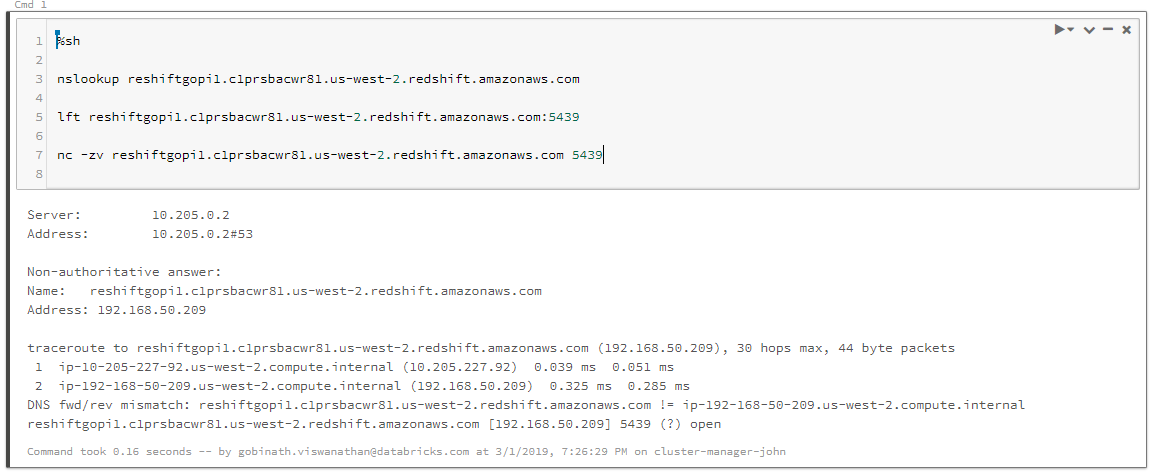
步驟1。測試連接
查看AWS控製台,確保目標VPC中的Redshift集群在線。執行以下Bash命令,查看是否可以建立到集群的連接:
%sh nc -zv%sh LFT : %sh Telnet
連接應該成功,並將端口顯示為打開。如果沒有,請轉步驟2。
[192.168.50.209] 5439(?)打開

步驟2。檢查VPC對等或DNS錯誤
如果連接失敗,出現以下錯誤之一,則問題是VPC對等或DNS錯誤。
- 以下錯誤碼表示VPC對等問題。執行步驟3。
xx.c1prsbaxxx.us -west-2.redshift.amazonaws.com[192.168.50.108] 5439(?):連接超時

- 如下錯誤碼表示DNS查詢錯誤:
redshift.c1prsbaxx.us -west-2.redshift.amazonaws.com:正向主機查找失敗:未知hos
- 在這種情況下,檢查:
- 紅移集群啟動。
- 主機名輸入正確。
- 紅移集群IP地址可以代替主機名。
- 使用nslookup檢查DNS解析:
網路資訊查詢<主機名>
- 如果這些檢查顯示正常,則錯誤可能在其他地方。執行步驟4。
步驟3。檢查VPC的對等網絡和DNS配置
如果步驟2顯示VPC對等連接或DNS問題:
1.驗證對等配置。
- 確保來自請求者和接受者VPC id的對等連接是正確的。請注意對等連接id、請求方的CIDR和接受方的CIDR。
- 確認目標VPC中的對等連接是活動的。

- 請確保Redshift VPC已開啟DNS解析檢查。完成後,請轉步驟4。
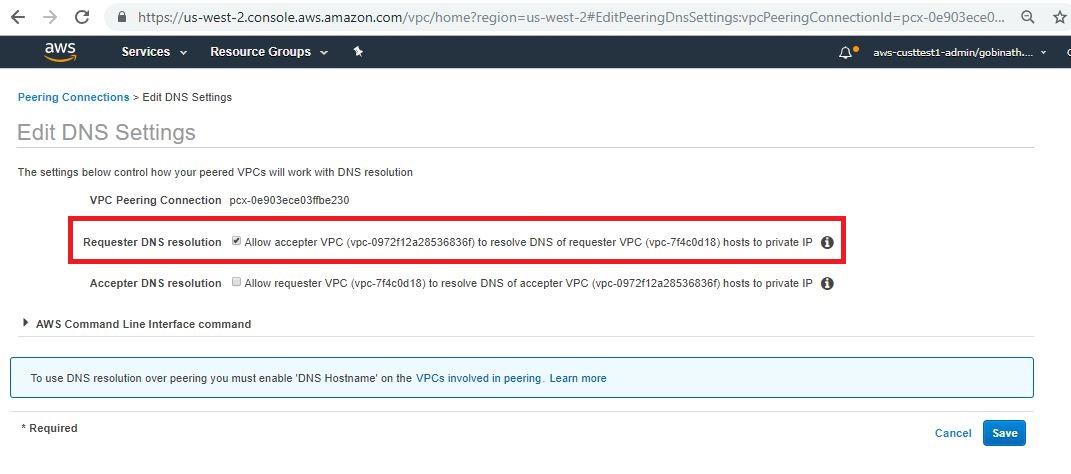
2.在“數據庫部署VPC”中檢查以下組件。
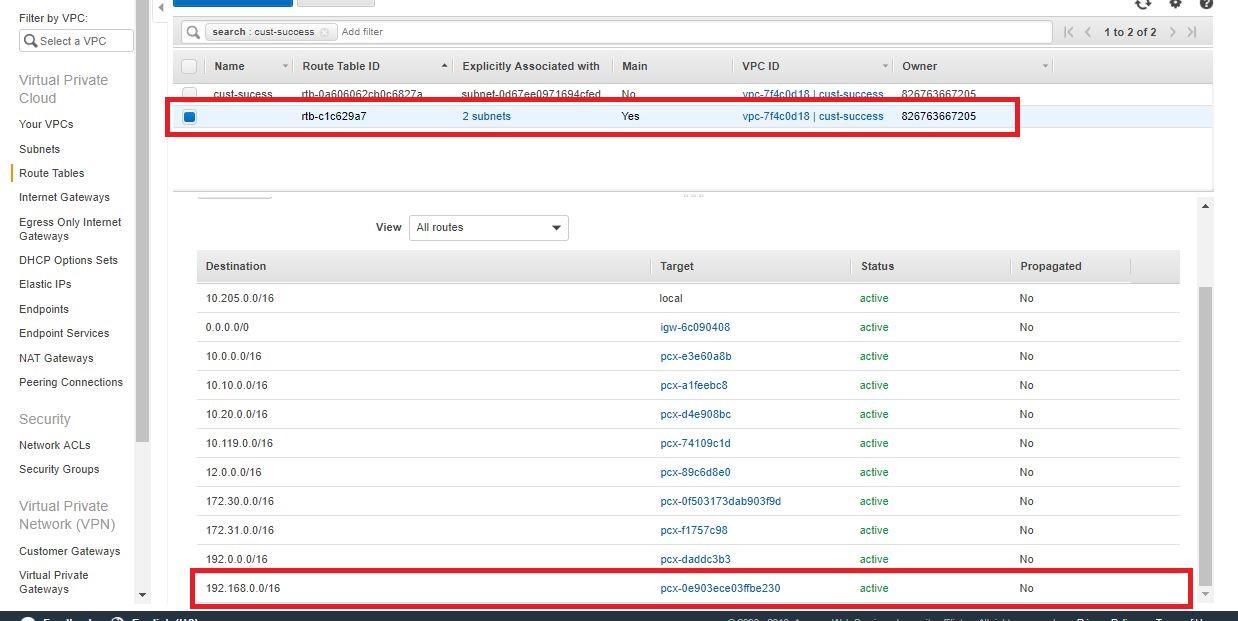
- 檢查部署VPC的路由表中添加了正確的目標VPC的CIDR (Redshift),路由到正確的目標,即對等連接id。
- 檢查附加到子網的NACL,並允許所有流量紅移,對於入站和出站規則。
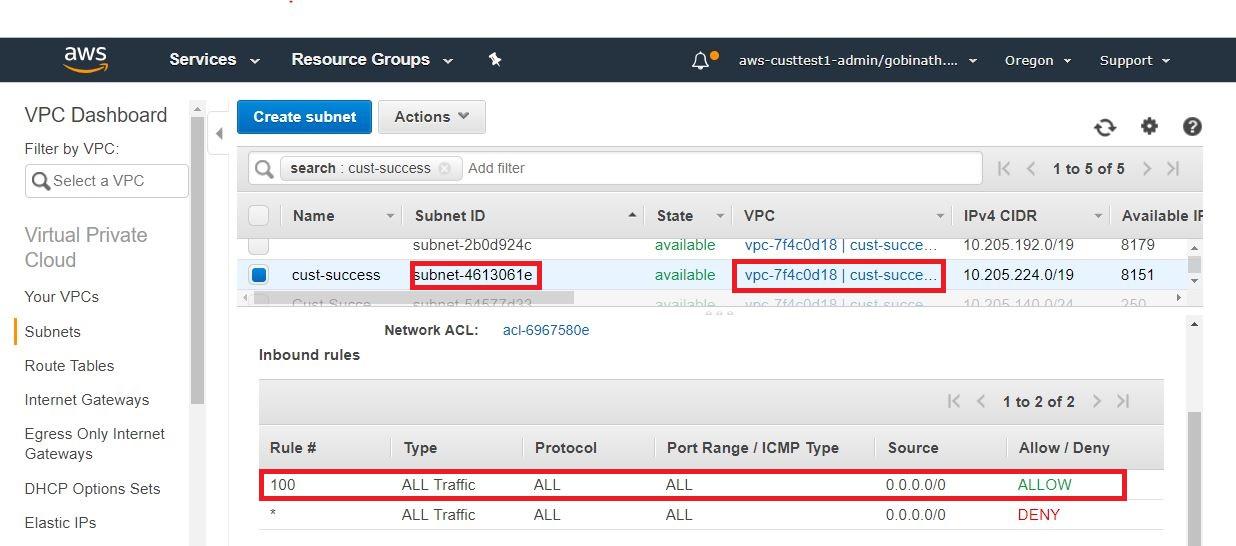
- 查看部署VPC的“安全組”。它應該是一個非托管安全組。確保端口5439(紅移)是對附加到Redshift的目標安全組開放的。
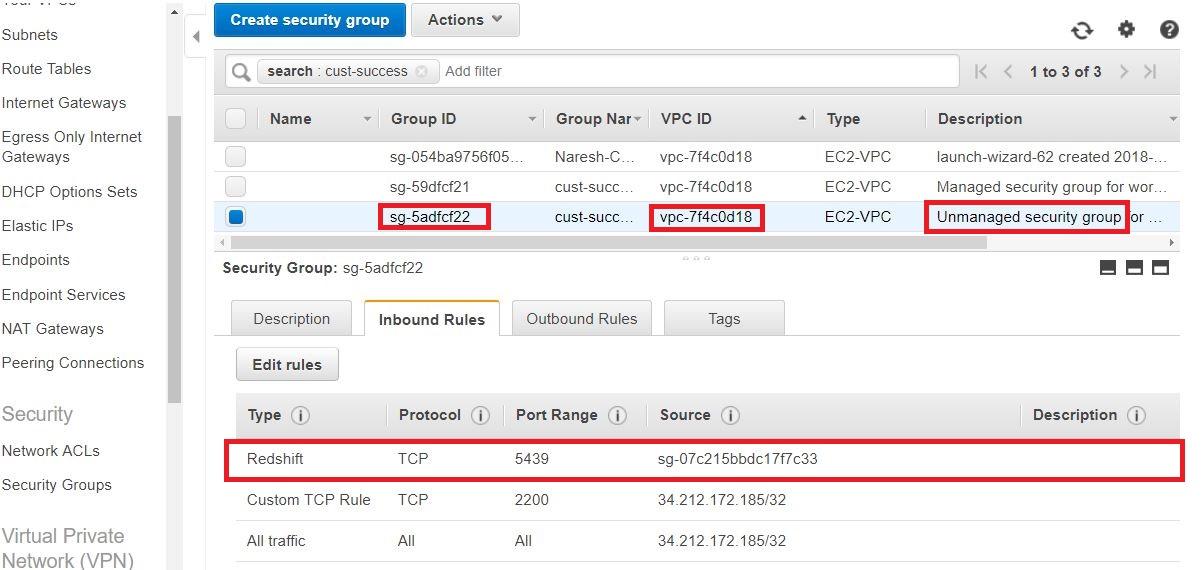
3.在Redshift VPC中檢查以下組件。
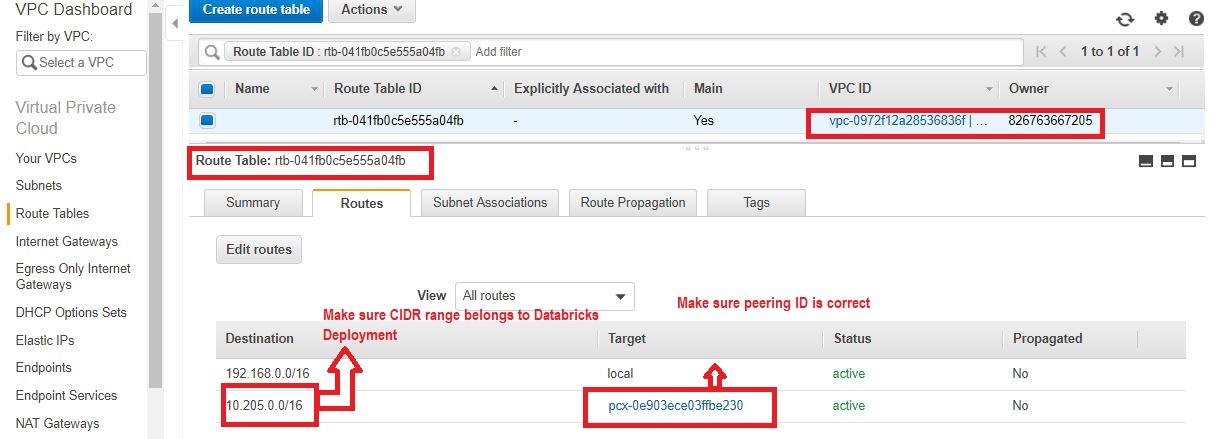
- 驗證部署VPC的路由表中添加了正確的目標VPC的CIDR (Databricks部署),並路由到正確的目標對等連接id。
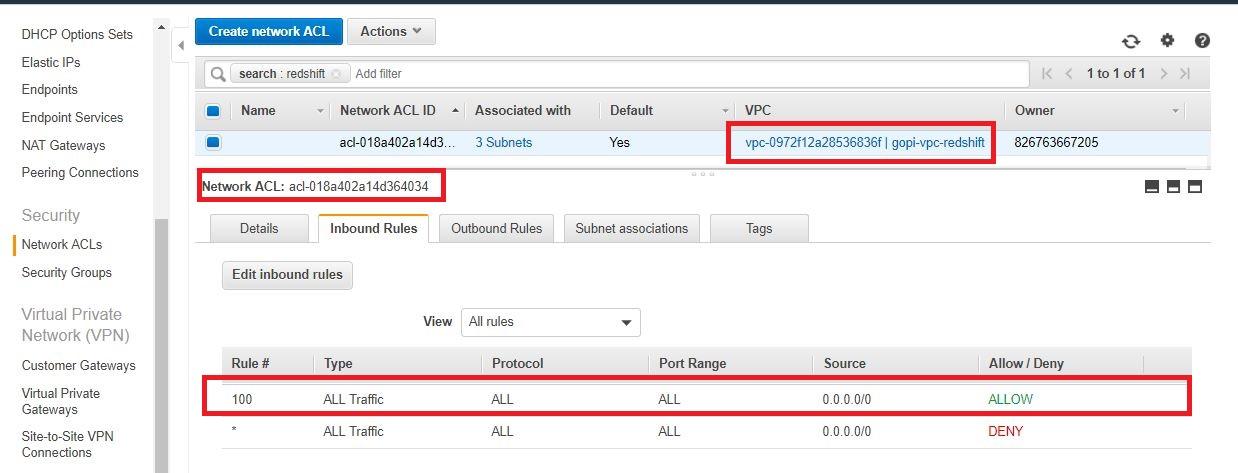
- 檢查NACL並允許所有來自紅移的流量(入站規則和出站規則)。
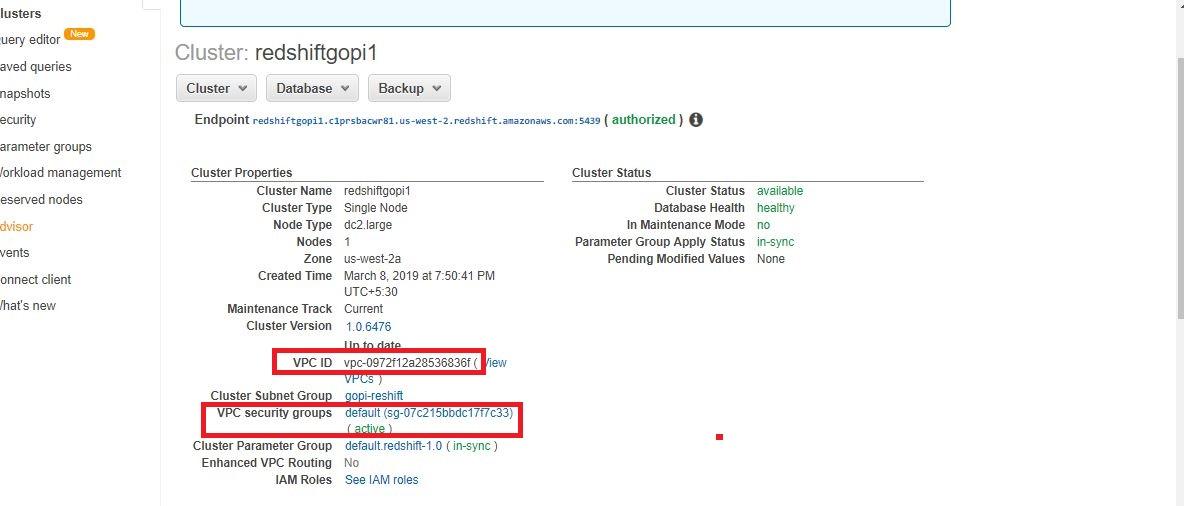
- 查看Redshift安全組對應的“Security Group”。確保端口5439(紅移)對目標安全組(即Databricks VPC內的非托管安全組)開放。
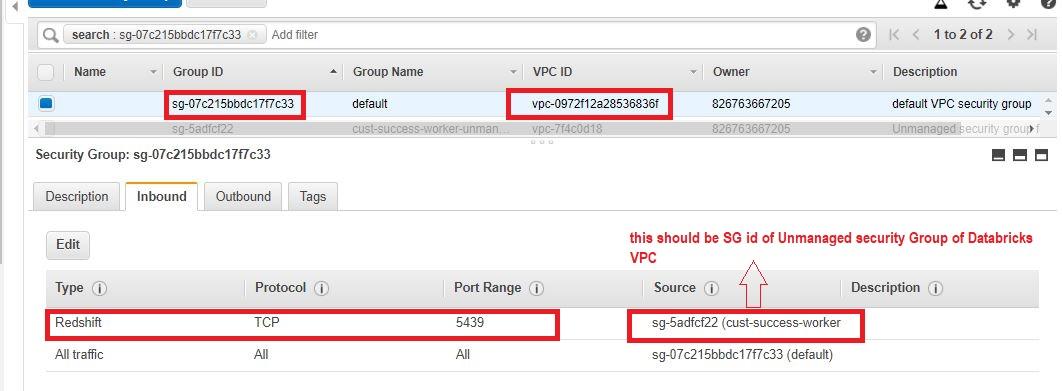
步驟4。驗證和驗證對等vpc之間的連通性
重新執行連接測試:
Nc -zv
連接測試應該成功。如果不是,請聯係數據支持。
[192.168.50.209] 5439(?)打開