
默認情況下,每個執行程序可用的內存量在Java虛擬機(JVM)內存堆中分配。這是由spark.executor.memory財產。
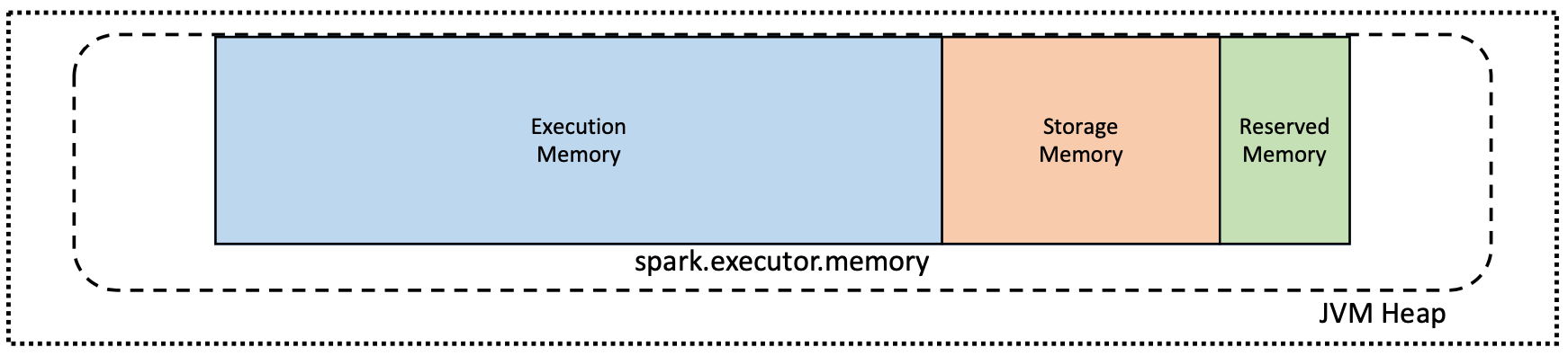
但是,在分配了大量內存的實例上觀察到一些意想不到的行為。隨著jvm內存大小的增加,垃圾收集器的問題變得很明顯。這些問題可以通過限製垃圾收集器管理下的內存量來解決。
選定的Databricks集群類型啟用了堆外模式,這將限製垃圾收集器管理下的內存量。這就是為什麼某些Spark集群具有spark.executor.memory值設置為整個集群內存的一小部分。
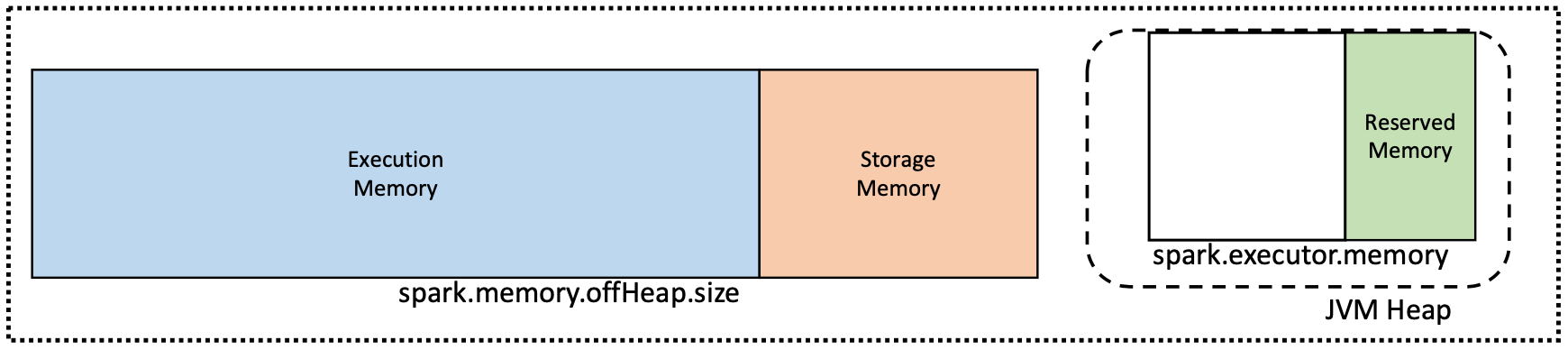
堆外模式由屬性控製spark.memory.offHeap.enabled而且spark.memory.offHeap.size在Spark 1.6.0及以上版本中可用。
AWS
以下Databricks集群類型啟用了堆外內存策略:
- c5d.18xlarge
- c5d.9xlarge
- i3.16xlarge
- i3en.12xlarge
- i3en.24xlarge
- i3en.2xlarge
- i3en.3xlarge
- i3en.6xlarge
- i3en.large
- i3en.xlarge
- m4.16xlarge
- m5.24xlarge
- m5a.12xlarge
- m5a.16xlarge
- m5a.24xlarge
- m5a.8xlarge
- m5d.12xlarge
- m5d.24xlarge
- m5d.4xlarge
- r4.16xlarge
- r5.12xlarge
- r5.16xlarge
- r5.24xlarge
- r5.2xlarge
- r5.4xlarge
- r5.8xlarge
- r5a.12xlarge
- r5a.16xlarge
- r5a.24xlarge
- r5a.2xlarge
- r5a.4xlarge
- r5a.8xlarge
- r5d.12xlarge
- r5d.24xlarge
- r5d.2xlarge
- r5d.4xlarge
- z1d.2xlarge
- z1d.3xlarge
- z1d.6xlarge
- z1d.6xlarge
Azure
以下Azure Databricks集群類型啟用了堆外內存策略:
- Standard_L8s_v2
- Standard_L16s_v2
- Standard_L32s_v2
- Standard_L32s_v2
- Standard_L80s_v2