
問題
的執行人選項卡顯示的內存比節點上實際可用的內存少:
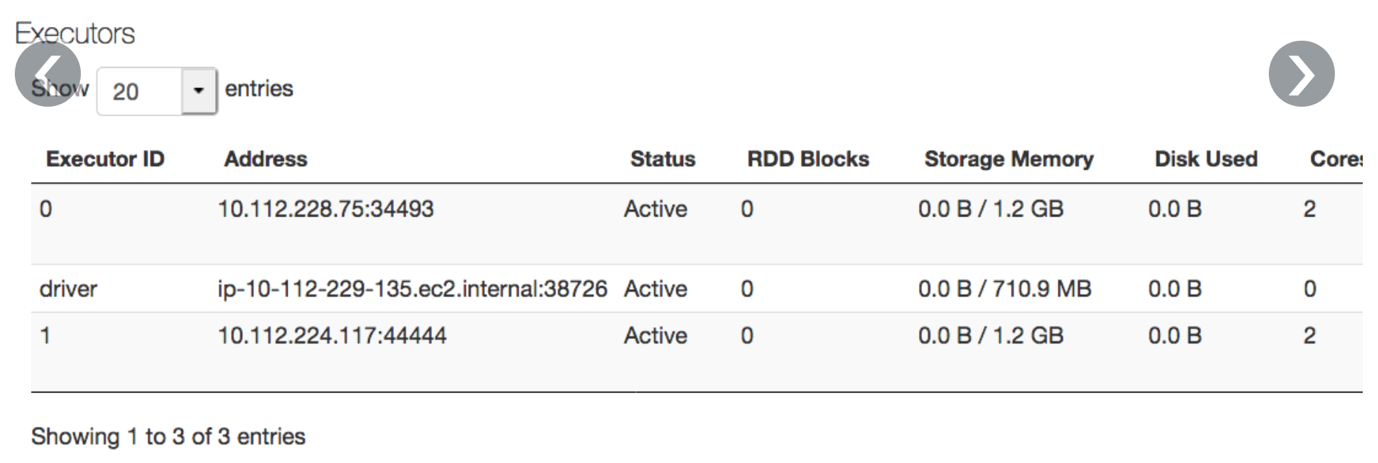
導致
顯示的總內存量小於集群上的內存,因為內核和節點級服務占用了一些內存。
解決方案
要計算可用內存量,可以使用用於執行器內存分配的公式(all_memory_size * 0.97 - 4800MB) * 0.8,地點:
- 0.97考慮內核開銷。
- 4800 MB的帳戶用於內部節點級服務(節點守護進程、日誌守護進程等)。
- 0.8是一種啟發式方法,用於確保運行Spark進程的LXC容器不會因為內存不足錯誤而崩潰。
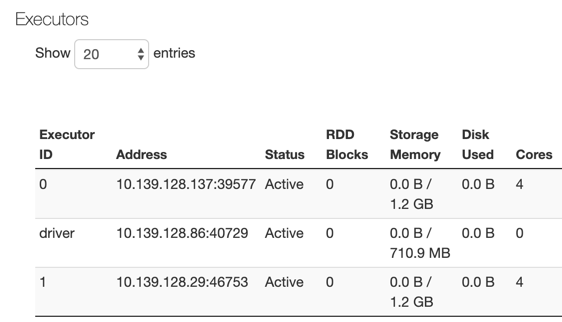
實例上用於存儲的總可用內存為(8192mb * 0.97 - 4800mb) * 0.8 - 1024= 1.2 gb。因為參數spark.memory.fraction默認值是0.6,大約是(1.2 * 0.6)= ~ 710mb可供存儲。
你可以改變spark.memory.fractionSpark配置(AWS|Azure)來調整此參數。計算新參數的可用內存如下所示:
- 如果使用具有8192 MB內存的實例,則它的可用內存為1.2 GB。
- 如果你指定了spark.memory.fraction0.8時,執行人選項卡中應該顯示:(1.2 * 0.8)Gb = ~ 960mb。