
問題
您正在嚐試讀取JSON文件。
您知道文件中有數據,但是Apache Spark JSON閱讀器返回一個零價值。
示例代碼
您可以使用此示例代碼重現該問題。
- 在DBFS中創建一個測試JSON文件。
% python dbutils.fs.rm(“dbfs: / tmp / json / parse_test.txt”)dbutils.fs.put(“dbfs: / tmp / json / parse_test.txt”,“””{“data_flow”:{“上遊 ":[{"$":{" 源”:“輸入”},“cloud_type ":""},{"$":{" 源”:“文件”},“cloud_type”:{“蔚藍”:“雲平台”,“aws”:“雲服務 Beplay体育安卓版本"}}]}} """) - 讀取JSON文件。
%python jsontest = spark.read.option("inferSchema","true").json("dbfs:/tmp/json/parse_test.txt") display(jsontest) - 結果是一個空值。
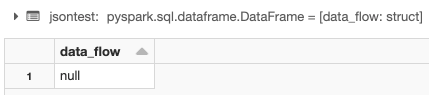
導致
- 在Spark 2.4及以下版本中,JSON解析器允許空字符串。隻有特定的數據類型,例如IntegerType被視為零空的時候。
- 在Spark 3.0及以上版本中,JSON解析器不允許空字符串。所有數據類型都會引發異常,除了BinaryType而且StringType.
有關更多信息,請參閱Spark SQL遷移指南.
示例代碼
示例JSON顯示了錯誤,因為數據有兩個相同的分類字段。
第一個cloud_typeEntry是一個空字符串。第二個cloud_type入口有數據。
"cloud_type":"" cloud_type":{"azure":"雲平台","aBeplay体育安卓版本ws":"雲服務"}
因為JSON解析器不允許在Spark 3.0及以上版本中使用空字符串,所以a零值作為輸出返回。
解決方案
設置火花配置(AWS|Azure|GCP)值spark.sql.legacy.json.allowEmptyString.enabled來真正的.這將配置Spark 3.0 JSON解析器以允許空字符串。
您可以在集群級別或筆記本級別設置此配置。
示例代碼
% python spark.conf.set(“spark.sql.legacy.json.allowEmptyString。enabled", True) jsontest1 = spark.read.option("inferSchema"," True ").json("dbfs:/tmp/json/parse_test.txt") display(jsontest1)
