奧克蘭體育棒球隊在2002年使用的數據分析和定量建模找出被低估的球員,創造一個有競爭力的陣容在有限的預算。這本書《點球成金邁克爾•劉易斯寫的,強調了一個“02賽季,給了一個內部了解團隊的戰略數據建模是多麼獨特,它的時間。快進20年——數據科學和定量建模的使用現在是一個常見的做法在所有體育特許經營權,並發揮了至關重要的作用,球隊建設,比賽當天操作和規劃。
2015年,美國職業棒球大聯盟(MLB)的介紹Statcast,一組攝像機和雷達係統安裝在30個大聯盟球場。Statcast生成7 tb的數據在一個遊戲,捕捉每一個可以想象到的數據點和公製俯仰、撞擊,運行和部署,係統收集和組織的消費。這次爆炸的數據實時分析遊戲創造了機會,和機器學習的應用,團隊現在能夠做出決策,影響比賽的結果,投球。這是20個賽季以來的首次使用數據建模棒球。這是一個內部看看職業棒球團隊使用技術磚創建現代《點球成金並獲得競爭優勢,數據團隊提供教練和球員在球場上。
圖1:鷹眼攝像機的位置和範圍在一個棒球體育場

圖2:數字代表事件期間被Statcast玩
圖3:Statcast采集的數據樣本
背景
數據團隊需要比以往更快地提供分析教練和球員,這樣他們就可以做出決定遊戲的展開。實時分析的決策可以顯著改變一場比賽的結果和一個團隊的季節。更令人難忘的一個例子是2020年世界係列的六場比賽。坦帕灣光芒洛杉磯道奇隊1 - 0領先在第六局時射線投手斯奈爾布雷克從堆當投手可以說是他職業生涯最好的比賽之一,主教練凱文決定現金說從他們的數據分析與見解。射線繼續輸掉比賽和世界係列。事後總是戴平光鏡,但它顯示出有效的數據已經成為遊戲。教練組任務數據團隊協助他們在關鍵的決策,例如,一個投手應該把另一個局或做一個替換,以避免潛在的傷害嗎?一個球員有更大成功的可能性偷從第一到二壘,或從第二到第三?
我有機會與很多MLB特許經營權並討論他們的優先級和數據分析相關的挑戰。通常,我聽到三個反複出現的主題數據團隊專注於最值在幫助設置他們的球隊在場上的成功:
- 速度:由於每一個大聯盟團隊訪問Statcast數據在一個遊戲,創建一個競爭優勢的一種方法是接收和處理數據的速度比你的對手。球之間的平均時間是23秒,這個時間代表一個基準Statcast數據可攝入教練和加工使用決策可以影響比賽的結果。
- 實時分析:團隊的另一個競爭優勢是創建實時的見解從他們的機器學習模型。一個例子是知道什麼時候從疲勞替代一個投手,一個模型解釋投手運動和數據點從球場本身和創建能夠預測性能的惡化投球。
- 易於使用:分析團隊遇到問題攝取大量的數據Statcast生產管道在本地電腦上運行時數據。這變得更加複雜當試圖擴展管道捕捉小聯盟數據與其他技術和集成。團隊需要合作,可伸縮的自動beplay娱乐ios化數據攝入與性能分析平台,創建遊戲影響決策的能力。Beplay体育安卓版本
棒球隊為這些重點和使用磚發展的解決方案其他幾個人。他們有形狀的現代版《點球成金的樣子。下麵是他們成功的框架以一種容易理解的方式來解釋。
獲得數據
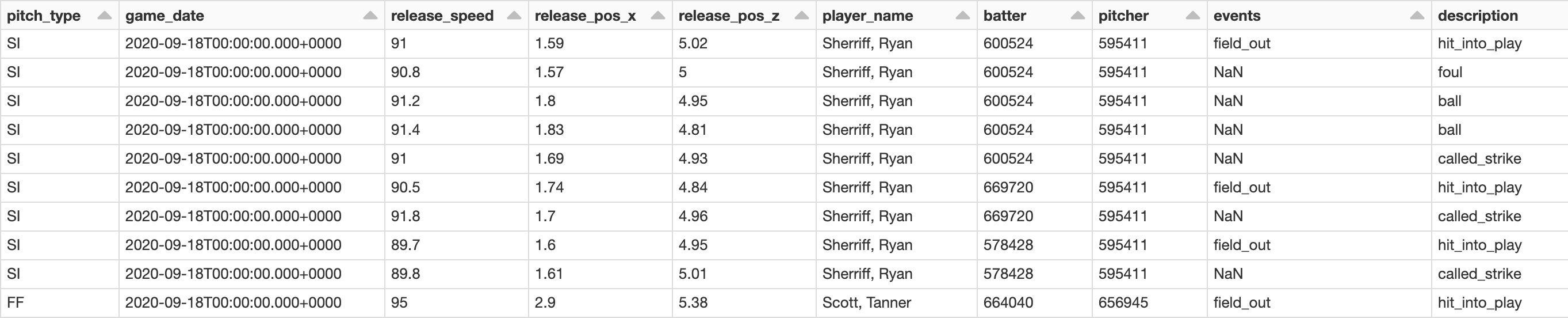
當一個投手投擲棒球,鷹眼攝像機收集數據並將其保存到一個應用程序,該應用程序使用一個團隊能夠訪問應用程序編程接口(API)屬於MLB。你能想到的一個API作為中間連接兩台計算機之間交換信息。這樣的工作方式是:用戶發送一個請求到一個API,該API確認用戶有權限訪問的數據,然後發送回請求的數據用戶消費。使用餐廳作為一個類比,客戶告訴服務員他們想要吃什麼,服務員告知廚房客戶想要吃什麼,服務員提供食物給客戶。服務員在這個場景中是API。
圖4:一個API是如何工作的例子使用餐廳的類比。
這個簡單的方法檢索數據稱為“批處理”風格的數據收集和處理、數據收集和處理一次。正如前麵提到的,然而,每23秒數據通常可以通過API(球之間的平均時間)。這意味著數據團隊需要連續請求API的方法被稱為“流”,不斷收集和處理數據。就像一個服務員很快就變得勞累滿足客戶的需求,使連續API請求數據在數據管道帶來了一些挑戰。beplay体育app下载地址這些數據團隊的幫助,但是,我們已經創建了代碼以適應不斷收集Statcast數據在一個遊戲。你可以看到下麵的代碼使用一個測試API的一個例子。
圖5:互動的一個API來檢索和存儲數據。
從pathlib進口路徑進口json類sports_api:def_init_(自我,端點,api_key):自我。端點=端點自我。api_key = api_key自我。連接=自我。端點+ self.api_keydeffetch_payload(自我、request_1 request_2 adls_path):url =f”{self.connection}&series_id ={request_1}{request_2}-99.”r = requests.get (url)json_data = r.json ()現在= time.strftime (“% Y % m % d % H % m % S”)file_name =f”json_data_out_{現在}”file_path =路徑(“dbfs: /)/路徑(adls_path) /路徑(file_name)dbutils.fs.put (str(file_path) json.dumps (json_data),真正的)返回str(file_path)
這段代碼將得到的數據API的步驟,並將其轉變成有用的信息,在過去,我們已經看到,會引起延遲的數據管道。使用這個代碼,Statcast數據自動保存為文件雲存儲和高效。下一步是攝取它進行處理。
與自動加載程序自動加載數據
音高和播放數據不斷保存到雲存儲,它使用磚可以自動吸收特性自動加載程序。自動加載程序掃描文件的位置保存在雲存儲和將數據加載到數據磚數據團隊開始改變它的分析。自動加載器是易於使用和非常可靠的縮放時攝取大批量數據批處理和流場景。換句話說,自動加載程序一樣適合小型和大型數據大小批量和流場景。下麵的Python代碼展示了如何使用自動加載程序流數據。
圖6:設置自動加載程序的流數據
df = spark.readStream。格式(“cloudFiles”)\.option \ (,). schema () \.load ()df.writeStream。格式(“δ”)\.option (“checkpointLocation”,)\.trigger () \.start ()
在這個過程的一個挑戰是處理的文件格式Statcast保存,一個叫做JSON格式。我們通常是特權處理數據,已經在一個結構化的格式,比如CSV文件類型,組織的列和行數據。JSON格式組織數據到數組和盡管它廣泛使用和采用,我仍然發現很難處理,特別是在大的尺寸。這是一個比較的數據保存在一個CSV格式和JSON格式。
圖7:比較CSV和JSON格式

很明顯這兩種格式的數據團隊喜歡。目標是負載Statcast JSON格式的數據並將其轉換為更友好的CSV格式。要做到這一點,我們可以使用半結構化數據支持可用在磚,基本語法允許我們提取和轉換的嵌套數據的JSON格式的結構化CSV格式風格。結合汽車裝載機的功能和簡單的半結構化數據支持創建一個強大的數據攝入方法使JSON數據簡單的變換。
使用磚的半結構化數據支持和自動加載程序
spark.readStream.format (“cloudFiles”)\.option (“cloudFiles.format”,“json”)\.option (“cloudFiles.schemaLocation”,”“)\.load (”“)\.selectExpr (“*”,“標簽:page.name”,#{提取“標簽”:{“頁麵”:{“名稱”:……}}}“標簽:page.id:: int”,#{提取“標簽”:{“頁麵”:{“id”:……}}}and casts toint“標簽:eventType”#提取{“標簽”:{“eventType”:…}})
作為中加載的數據,我們將它保存到一個三角洲進一步表開始使用它。三角洲湖是一個開放的格式存儲層帶來的可靠性、安全性、和性能數據流和批處理和湖是一個具有成本效益的基礎,高度可伸縮的數據平台。Beplay体育安卓版本半結構化的支持與δ允許您如果需要保留一些嵌套數據。語法允許靈活性維護三角洲內嵌套的數據對象作為列表而不需要平所有的JSON數據。棒球分析團隊使用增量版本Statcast數據和執行來運行他們的特定需求分析,組織在一個友好的結構化的格式。
自動加載程序寫入數據到三角洲表作為一個流
#定義模式和輸入、檢查點和輸出路徑。read_schema = (“int id”,+“firstName字符串”,+“middleName弦。”+“姓字符串”,+“性別字符串,”+“生日時間戳”,+“ssn弦。”+“工資int”)json_read_path =' / FileStore / streaming-uploads / people-10m 'checkpoint_path =“/ mnt /δ/ people-10m /檢查站”save_path =“/ mnt /δ/ people-10m”
people_stream =(火花\.readStream \. schema (read_schema) \.option (“maxFilesPerTrigger”,1)\.option (“多行”,真正的)\. json (json_read_path))
people_stream。writeStream \。格式(“δ”)\.outputMode (“添加”)\.option (“checkpointLocation”checkpoint_path) \.start (save_path)
不斷自動加載程序數據在每一個音高,半結構化數據轉換成可用格式的支持,和三角洲湖組織使用,數據團隊現在可以營造出他們的團隊競爭優勢分析。
機器學習的見解
回憶的射線拉斯奈爾布雷克丘在世界大賽——這個決定來自見解教練看到在他們的預測模型。斯奈爾的統計分析的曆史Statcast比利斯奈爾個sportingnews.com表示提供的數據沒有投了六局2019年7月以來,較低的概率顯著麵糊當麵對他們第三次遊戲,和被隊友尼克•安德森鬆了一口氣的音高數據顯示是最強的意見MLB 0.55自責分率0.49(時代),散步和打局投球(鞭子)在2020年他19場常規賽。這樣的預測模型分析數據實時並提供證據和建議教練使用做出重要的決定。
機器學習模型是相對容易的構建和使用,但是數據團隊常常難以實現用例流。添加模型是如何管理的複雜性和存儲和機器學習可以很快變得遙不可及。幸運的是,數據團隊使用MLflow來管理他們的機器學習模型和實現他們的數據管道。MLflow端到端機器學習是一個開源的平台來管理生Beplay体育安卓版本命周期,包括支持跟蹤預測結果,注冊表的集中模型使用模型和其他發展和服務能力使用模型的數據管道。
圖10:MLFlow概述

實現機器學習算法和模型實時用例,團隊使用的數據模型注冊一個模型能夠坐在三角洲表讀取數據並創建預測,然後在比賽中使用。這裏有一個例子如何使用機器學習模型,而數據是自動加載和自動加載程序:
得到一個機器學習模型從注冊表和自動加載器使用它
#從模型得到模型注冊表模型= mlflow.spark.load_model (model_uri =f”模型:/{model_name}/{“生產”}”)#從青銅表讀取數據流=引發事件。readStream \。格式(“δ”)\# .option (“cloudFiles。maxFilesPerTrigger”, 1) \. schema \(模式).table (“baseball_stream_bronze”)#流穿過模型model_output = model.transform(事件)#寫流銀δ表事件。writeStream \。格式(“δ”)\.outputMode (“添加”)\.option (“checkpointLocation”,“/ tmp /棒球/”)\.table (“default.baseball_stream_silver”)
輸出一個機器學習模型創建可以顯示在數據可視化或儀表板和用作打印出來或在平板電腦上共享一個遊戲。MLB特許經營在磚發展的有趣的用例,整個賽季在比賽中使用。預測模型是專有的個人團隊,但是這是一個實際用例運行在磚的實時分析,展示了權力的棒球。
帶它一起旋轉比率和黏糊糊的東西
美國職棒大聯盟,推出了新規則2021賽季為了阻止投手的使用“黏糊糊的東西,”一個物質隱藏在手套,腰帶,或帽子,當應用於棒球可以大大增加球的旋轉比例,使打者很難被擊中。10場比賽的規則中止投手發現使用黏糊糊的東西。教練在反對團隊能夠請求一個裁判檢查這種物質如果他們懷疑一個投手在比賽中使用它。自旋率是一個數據點,被鷹眼攝像機和實時分析和機器學習,團隊現在能夠做出合理的請求裁判希望捕捉投手使用材料。
圖12:說明如何旋轉影響
圖13:趨勢自轉速度快球每賽季規則的介紹之後,6月3日,2021年
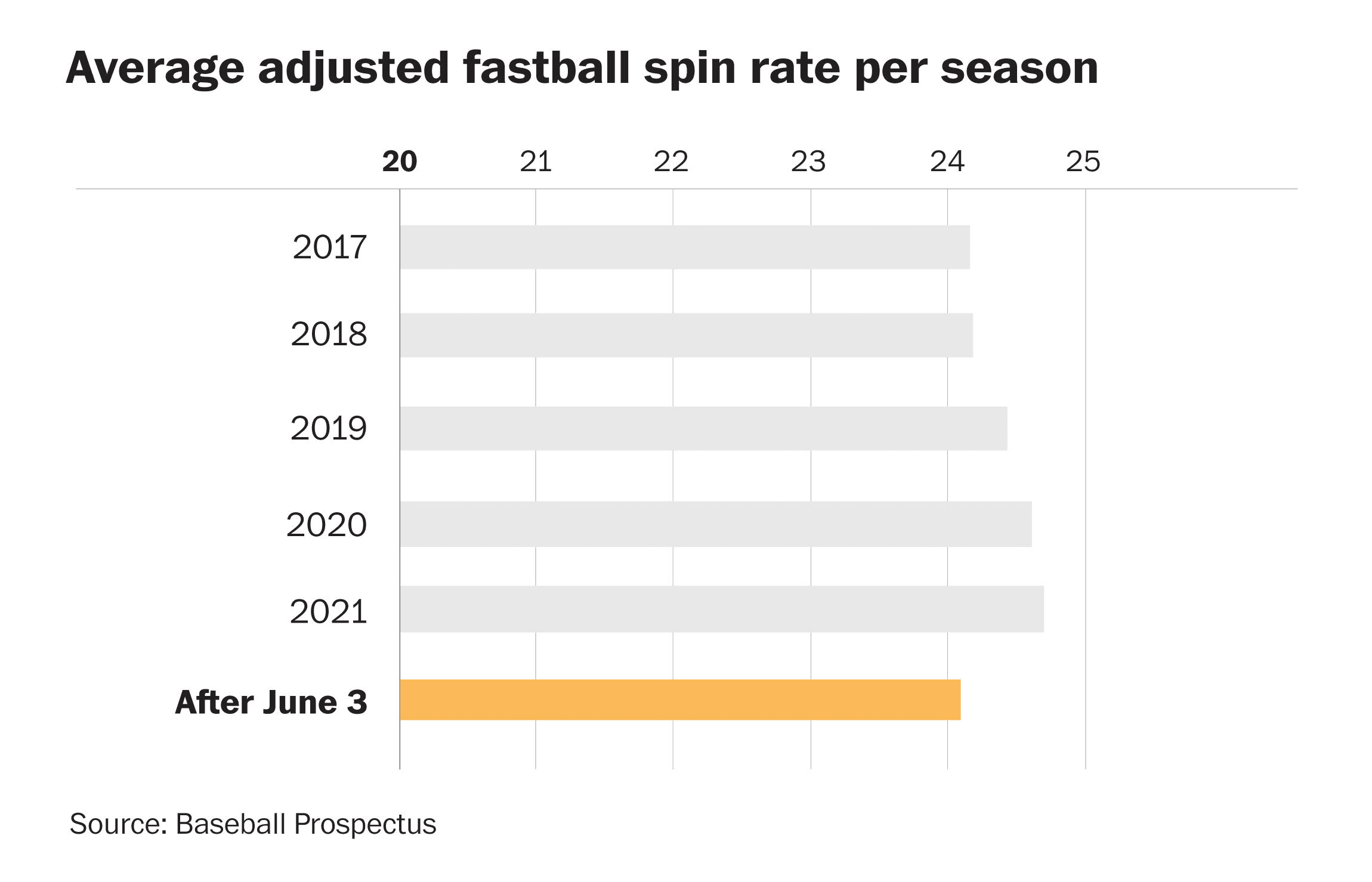
上述相同的框架後,我們攝取Statcast音高和音調的數據有一個儀表板追蹤球的旋轉比所有投手在所有大聯盟比賽。使用機器學習模型,預測被發送到儀表板國旗離群值對曆史數據和投手的表現活躍的遊戲,可以提醒教練時超出預期範圍的模型。與汽車裝載機、三角洲湖和MLflow攝入和分析所有數據在實時發生。
圖14:實時檢測指示板粘的東西
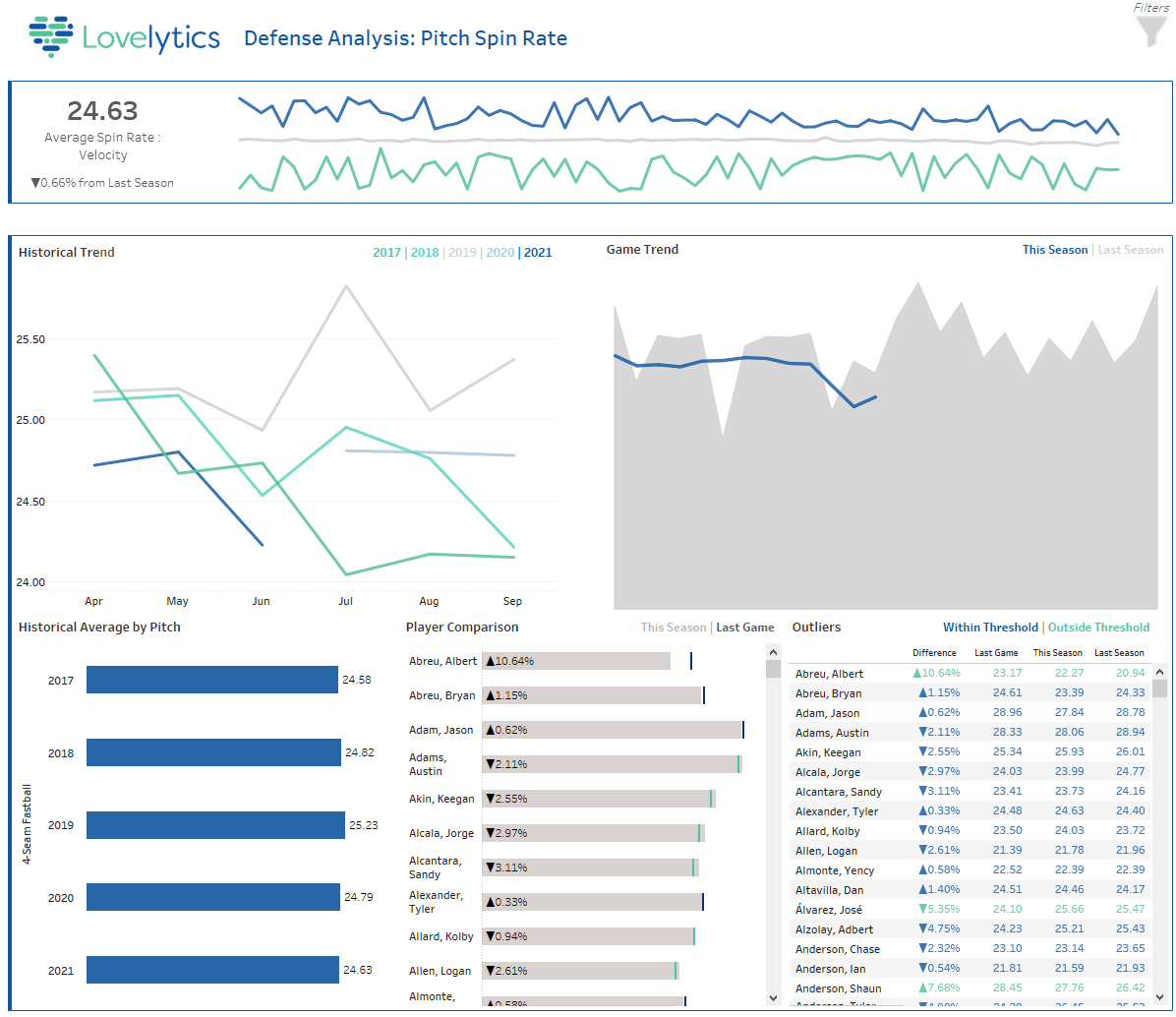
技術Statcast和磚帶來的實時分析運動和變化的模式意味著什麼是一個數據驅動的團隊。隨著數據量持續增長,擁有正確的架構來捕獲實時見解至關重要保持領先一步的競爭。實時架構將日益重要,團隊獲得和發展的球員,本賽季計劃和發展特許經營的分析增強方法。詢問我們的解決方案加速器與磚的伴侶Lovelytics,為球隊提供了所有他們需要的資源快速創建用例中描述的這個博客。